Matplotlib的API过于复杂。Seaborn 基于Matplotlib核心库进行了更高级的API封装,可以轻松的画出更复杂的图形。
安装
1
2
3
4
5
|
# 安装
pip install seaborn
# 导入
import seaborn as sns
|
使用
- 绘制单变量:distplot()
- 绘制双变量:jointplot()
- 绘制成对的双变量:pairplot()
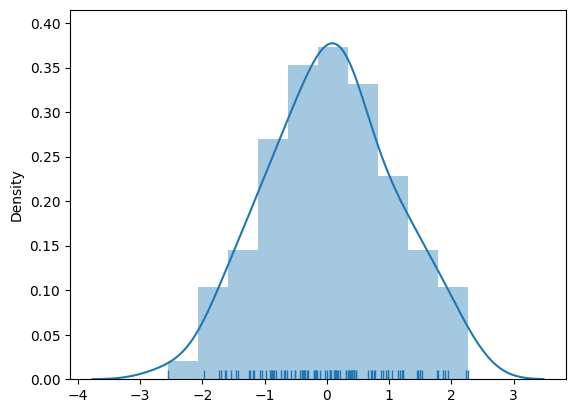
单变量分布
直方图
1
2
3
4
|
seaborn.distplot(a=None, bins=None, hist=True, kde=True, rug=False, fit=None,
hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,
color=None, vertical=False, norm_hist=False, axlabel=None,
label=None, ax=None, x=None):
|
a:观察的数据bins:用于控制条形的数量hist:接受布尔类型,表示是否绘制值(标注)直方图kde:表示是否绘制高斯核密度估计曲线rug:表示是否在支持的轴上绘制rugplot
核密度估计:在概率论中用来估计位置的密度函数,属于非参数检验方法之一,可以比较直观的人看出数据样本本身的分布特征
1
2
3
4
5
6
|
import seaborn as sns
import numpy as np
np.random.seed(0)
arr = np.random.randn(100)
ax = sns.distplot(arr, bins=10, hist=True, kde=True, rug=True)
|
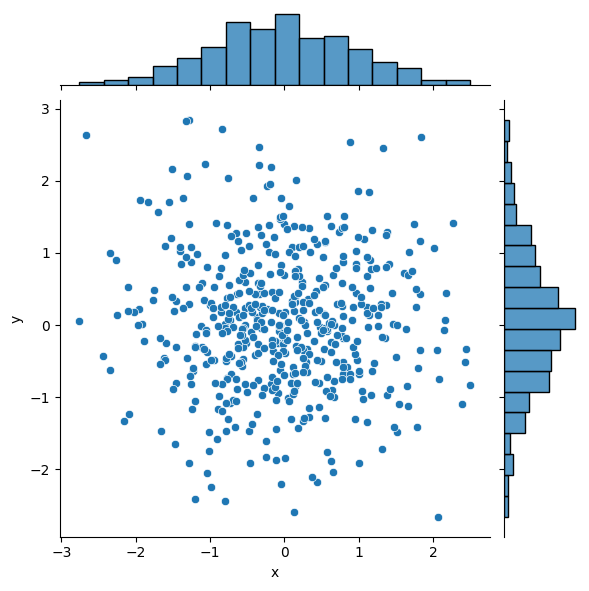
双变量分布
散点图
1
2
3
4
5
6
7
|
seborn.jointplot(
data=None, *, x=None, y=None, hue=None, kind="scatter",
height=6, ratio=5, space=.2, dropna=False, xlim=None, ylim=None,
color=None, palette=None, hue_order=None, hue_norm=None, marginal_ticks=False,
joint_kws=None, marginal_kws=None,
**kwargs
)
|
参数说明:
kind:表示绘制图形的类型stat_func:用于计算有关关系的统计量并标注图color:表示绘图元素颜色size:用于设置图的大小ratio:表示中心图与侧边图的比例,该参数的值越大,则中心图的占比会越大space:用于设置中心图与侧边图的间隔大小
1
2
3
4
5
6
|
import pandas as pd
df = pd.DataFrame({"x": np.random.randn(500), "y": np.random.randn(500)})
# df.head()
sns.jointplot(x="x", y="y", data=df, kind="hex")
|
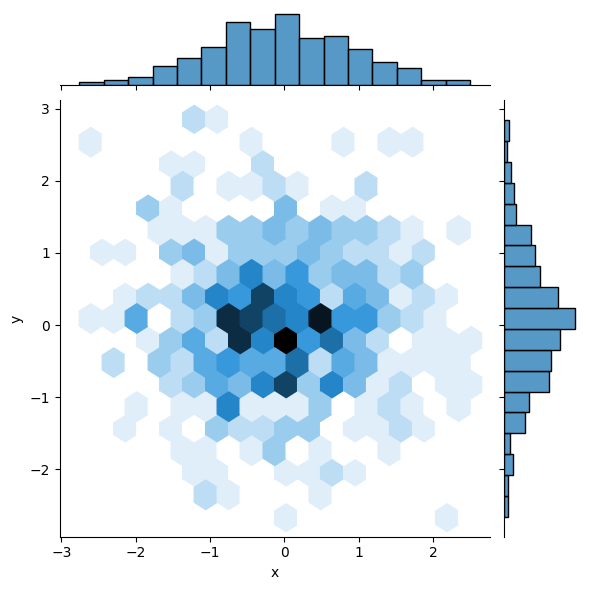
二维直方图
将kind设置为hex
核密度估计图形
将kind设置为kde
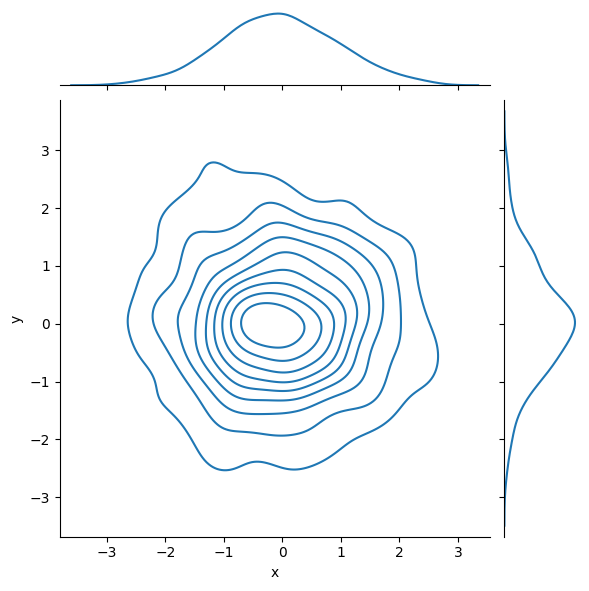
成对的双变量分布
要想从数据集中绘制出成对的双变量分布,可以使用pairplot()函数实现,该函数会创建一个坐标轴矩阵,并且对现实Dataframe
对象中的美队变量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布
1
2
3
|
# 加载seaborn中内置的数据集
dataset = sns.load_dataset("iris")
dataset.head()
|

1
2
|
# 绘制多个成对的双变量分布
sns.pairplot(dataset)
|
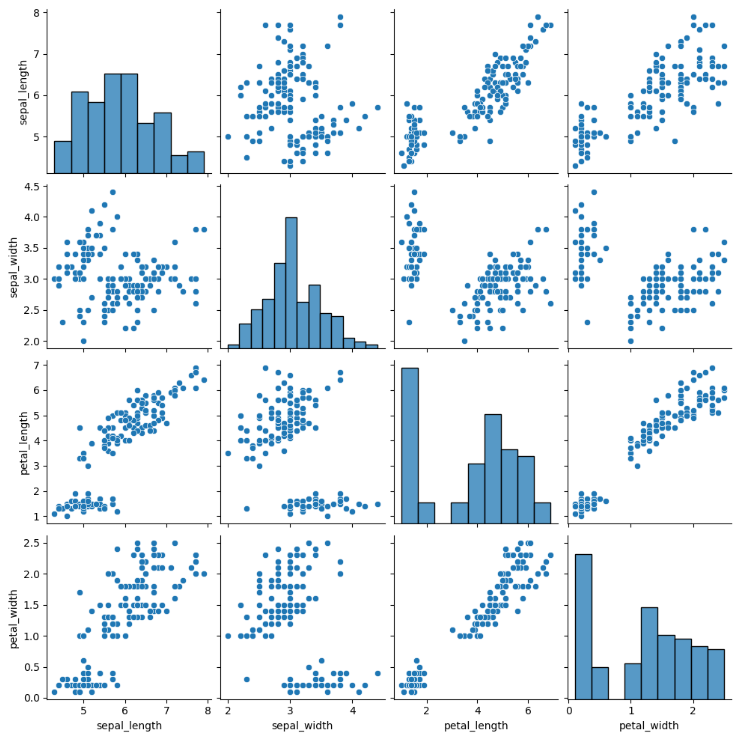
可以看出变量和变量之间的关系,比如说从倒数第二张图中可以看出petal_width和petal_length可能存在某种线性关系。
分类数据绘图
数据集中的数据有很多中,除了连续型数据,最常见的就是类别型数据了,如:人的性别、学历、爱好等。
SeaBorn针对这些数据提供了一下几个函数:
- 分类数据三点图:
swarmplot()、stripplot()
- 类数据的分布图:
boxplot()、violinplot()
- 分类数据的统计估算图:
barplot()、pointplot()
类散点图
- 通过
stripplot()函数绘制
1
2
3
4
5
6
7
|
def stripplot(
data=None, *, x=None, y=None, hue=None, order=None, hue_order=None,
jitter=True, dodge=False, orient=None, color=None, palette=None,
size=5, edgecolor="gray", linewidth=0,
hue_norm=None, native_scale=False, formatter=None, legend="auto",
ax=None, **kwargs
):
|
x,y,hue:用于绘制长格式数据的输入data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,负责将作为长格式jitter:表示抖动的程度(仅仅沿着类别轴),当很多数据重叠的时候,可以指定抖动的数量或者设置为Tue使用默认值
- 通过
swarmplot()绘制,该函数绘制的所有数据点都不会重叠
1
2
3
4
5
|
import seaborn as sns
# 导入内置数据集
data = sns.load_dataset("tips")
data.head()
|

1
|
sns.stripplot(x="day", y="total_bill", data=data)
|
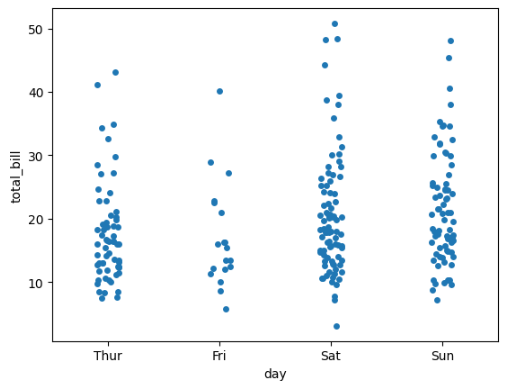
1
2
|
# 设置hue
sns.stripplot(x="day", y="total_bill", data=data, hue="time")
|
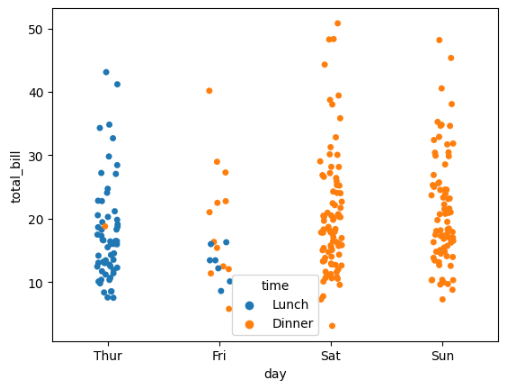
使用swarmplot()函数绘制:
1
|
sns.swarmplot(x="day", y="total_bill", data=data, hue="time")
|
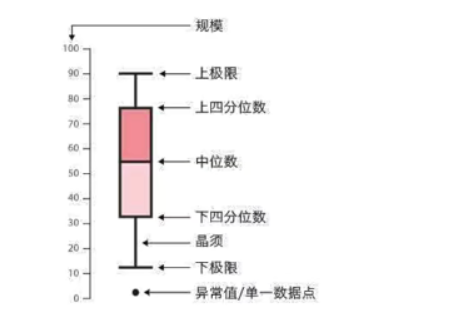
箱型图
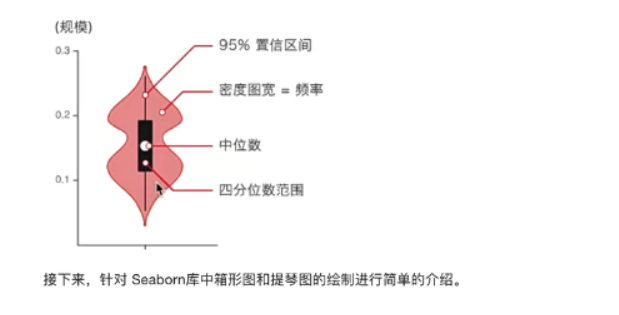
又称为盒须图、盒式图、箱线图。能显示出一组数据的最大值、最小值、中位数、以及上下四分位数
可以使用boxplot()函数来绘制箱型图
1
2
3
4
5
6
|
def boxplot(
data=None, *, x=None, y=None, hue=None, order=None, hue_order=None,
orient=None, color=None, palette=None, saturation=.75, width=.8,
dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None,
**kwargs
):
|
palette:用于设置不同级别色相的颜色变量。如:palette=["r", "g", "b", "y"]saturation:用于设置数据显示的颜色饱和度。使用小数表示
小提琴图
用于显示数据分布以及概率密度。