Hadoop简介
目录
Hadoop版本和优势
三大发行版本
Hadoop的三大发行版本:
- Apache:是最原始最基础的版本,适合入门
- Cloudera: 大型互联网企业中使用较多
- Hortonworks:文档较好
Apache
Cloudera
- 2008年成立的
Cloudera公司是最早将Hadoop商用的公司 - 2009年
Hadoop的创始人Doug Cutting加盟Cloudrea公司 Cloudera的主要产品是CDH,CDH是Cloudera的Hadoop的发行版本,完全开源,比Apache Hadoop在兼容性和安全性,稳定性上有所增强
Hortonworks
2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建的。
公司成立之初就就吸纳了大约25至30名专门 研究Hadoop的雅虎工程师,上述工程师在2005年开始协助雅虎开发Hadoop,贡献了Hadoop的80%的代码。
Hadoop优势
- 高可靠性:多个副本
- 高扩展性:在集群之间分配任务及数据,方便扩展数以千计的节点
- 高效性:在
MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度 - 高容错性:能够自动将失败的任务重新分配
Hadoop组成
Hadoop 1.x时代
Hadoop中的MapReduce同事处理业务逻辑运算和资源调度,耦合性较大

Hadoop 2.x时代
增加了Yarn,Yarn只负责资源的调度,MapReduce只负责运算
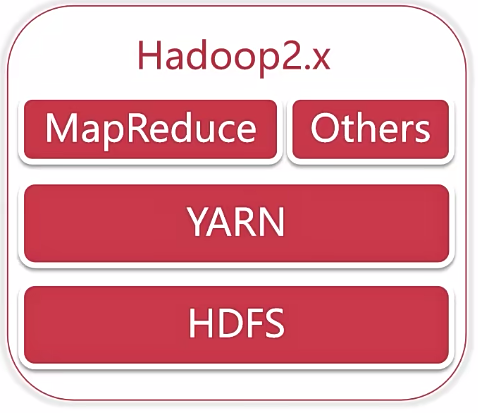
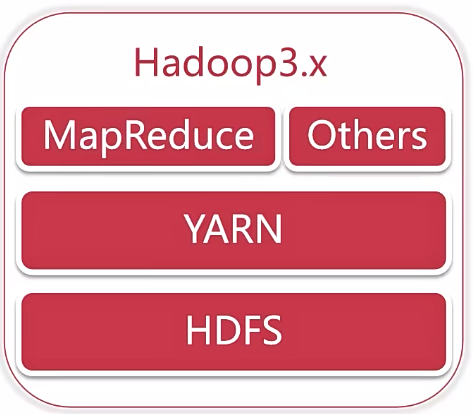
Hadoop 3.x时代
java修改为支持8及以上HDFS支持纠删码- 纠删码是一种比副本存储更加节省空间的一种数据持久化方案
HDFS支持多NameNodeMap Reduce任务级本地化- 多重服务默认端口变更
Hadoop 三大核心组件介绍
Hadoop的主要三大核心组件:HDFS+MapReduce+Yarn

HDFS架构
分布式存储:负责海量数据存储
-
NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件块列表所在的DataNode等。
-
DataNode(dn):在本地文件系统存储文件块数据,以及数据的校验和。
-
Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
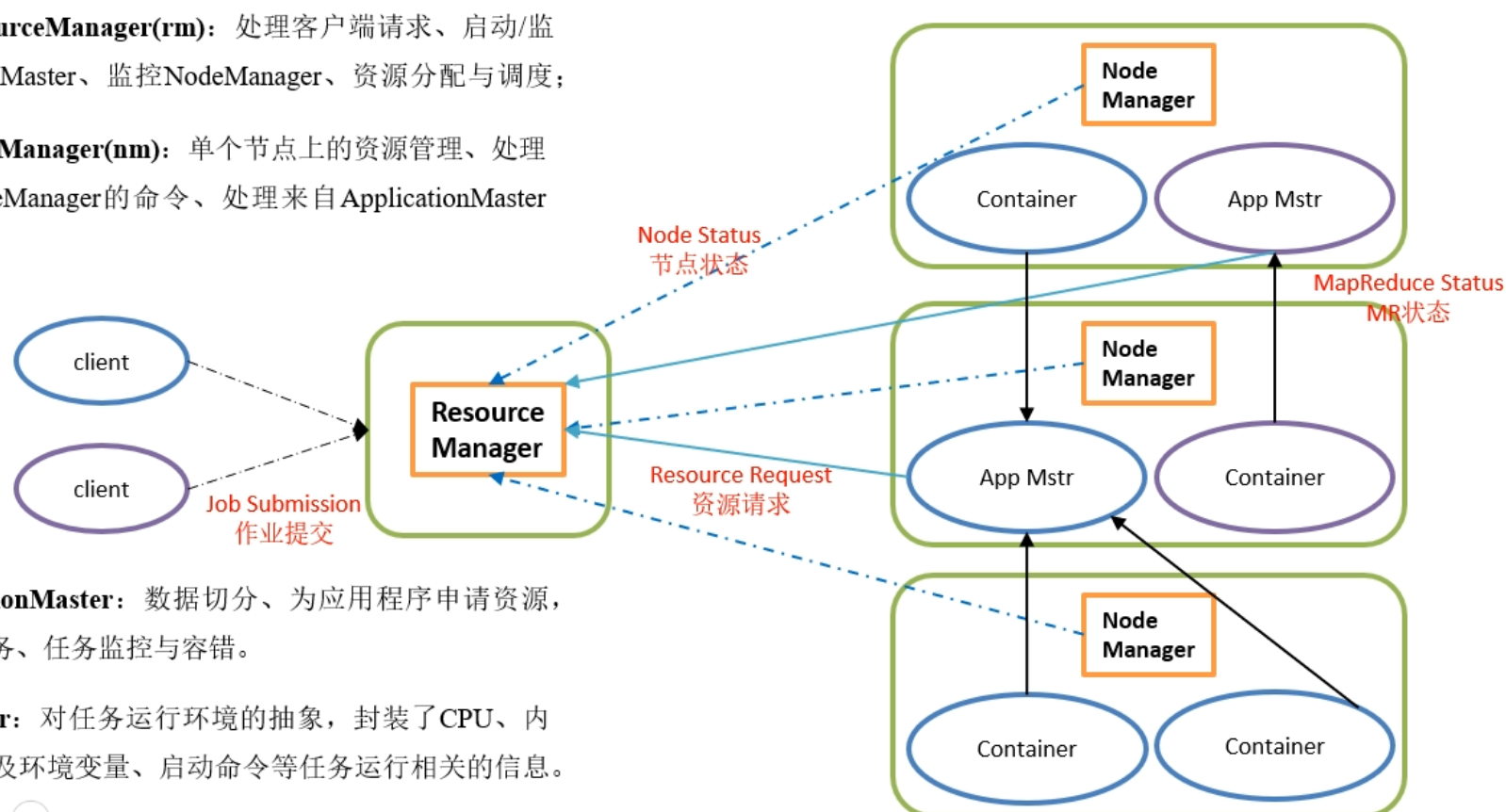
YARN架构
集群资源的管理和调度
- ResourceManager(rm):处理客户端请求、启动/监控
ApplicationMaster、监控NodeManger、资源分配与调度 - NodeManger(nm):单个节点上的资源管理、处理来自
ResouceManger的命令、处理来自ApplicationMaster的命令 - ApplicationMaster:数据切分、为应用程序申请资源并分配给内部任务、任务监控与容错。
- Container:对任务运行的环境的抽象,封装了CPU、内存等多位资源一级环境变量、启动命令等任务运行相关信息。
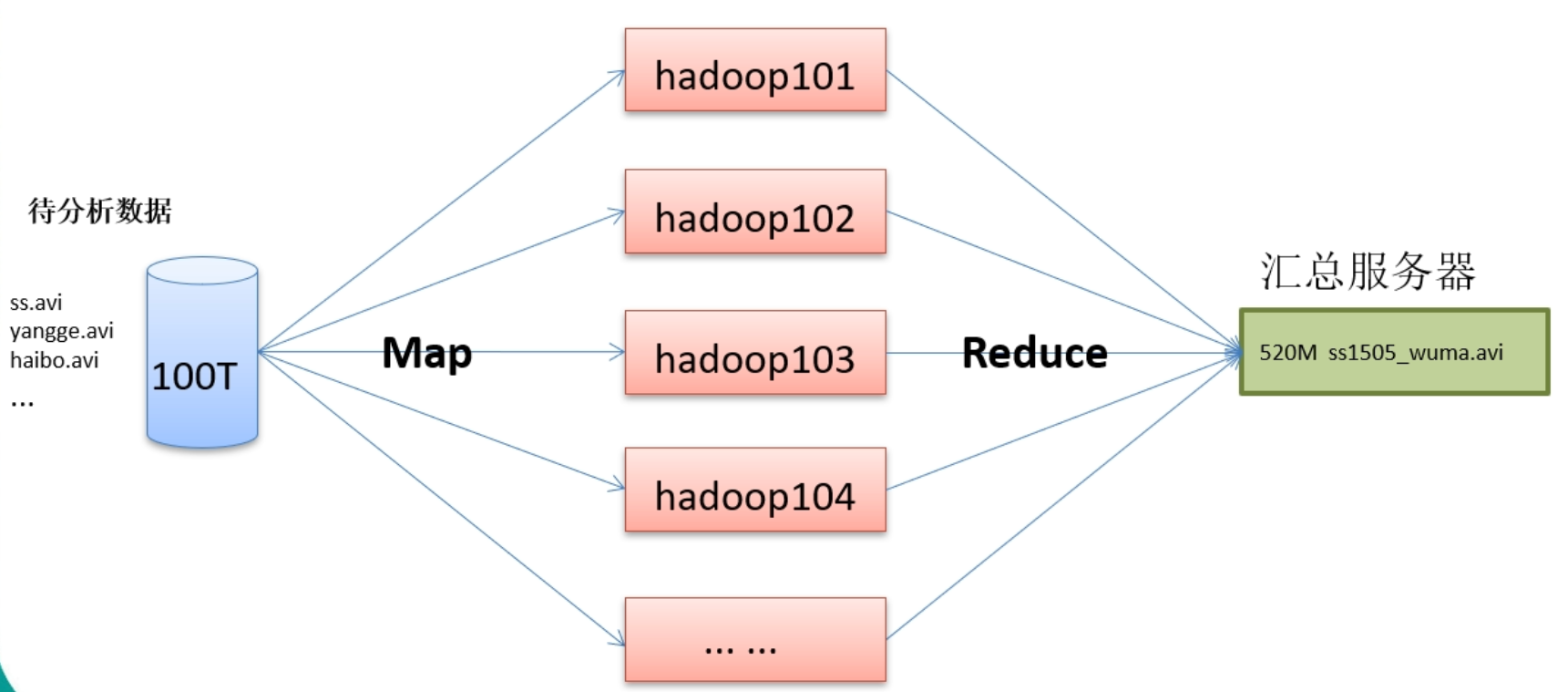
MapReduce架构
分布式计算框架
MapReduce将计算过程分成两个阶段:Map和reduce
- Map阶段并行处理输入的数据
- Reduce阶段对Map结果进行汇总
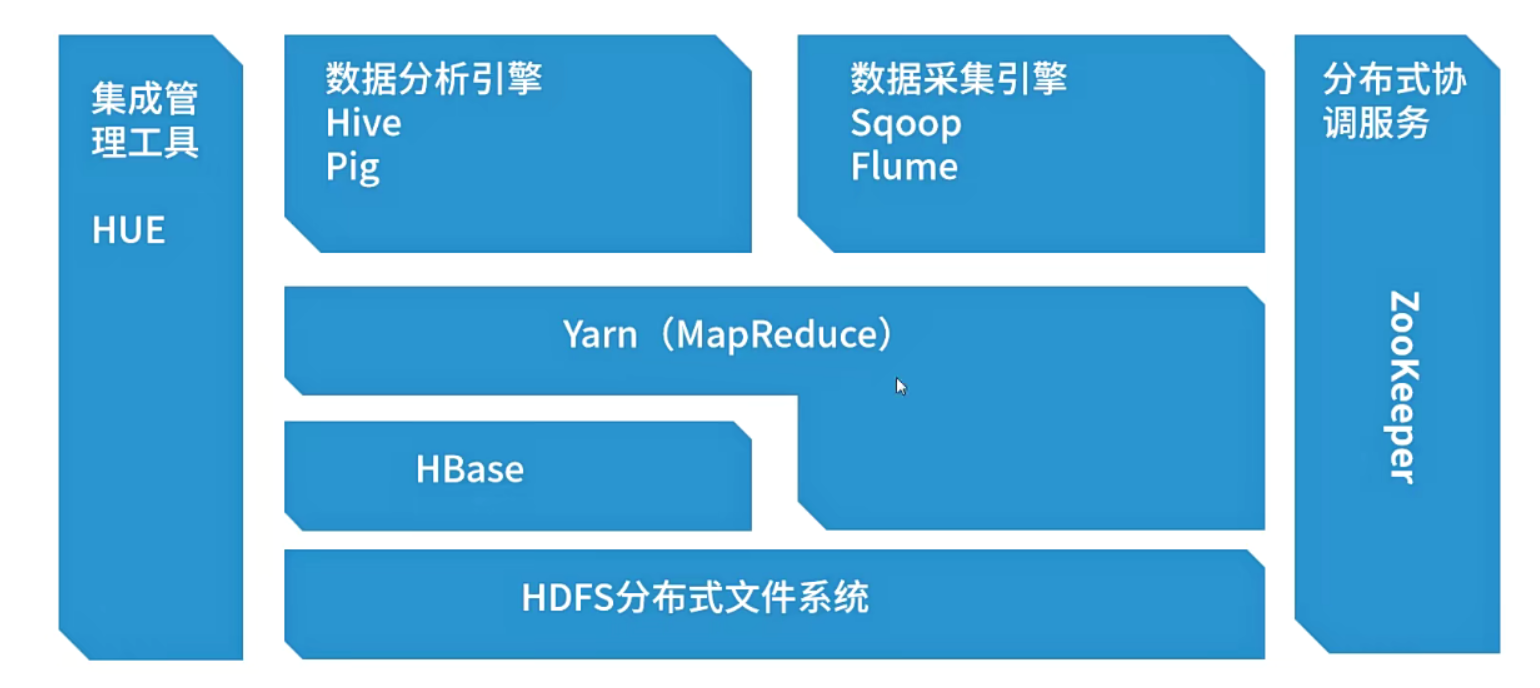
大数据的生态系统
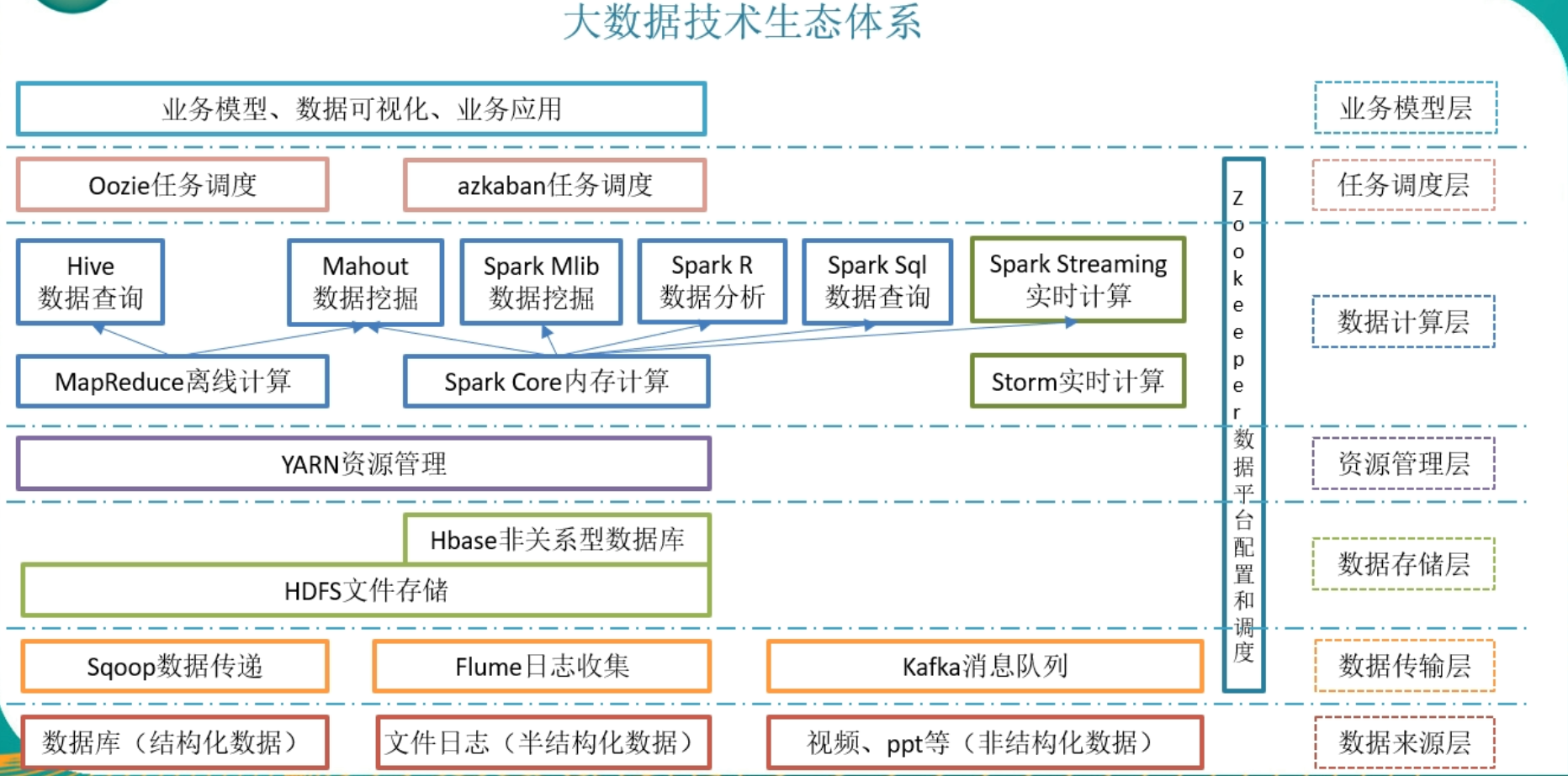
Hadoop生态
Hadoop安装
下载方式
- 官网https://hadoop.appache.org
- 历史归档:https://archive.apache.org/dist/hadoop/common/
- 推荐使用国内镜像:https://mirrors.tuna.tsinghua.edu.cn/apache
- 本次使用:https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
配置SSH
|
|
安装JDK环境
安装Hadoop
上传安装包并解压:
|
|
- bin:
- etc:配置
- sbin:启动脚本
配置环境变量
为了后面使用方便将hadoop的bin和sbin目录添加只环境变量中
|
|
修改配置文件
- 修改
hadoop-env.sh