编译原理-汇编程序设计
目录
汇编器
编译器: 将高级语言翻译为汇编语言
汇编器: 将汇编语言翻译为目标机器的二进制代码
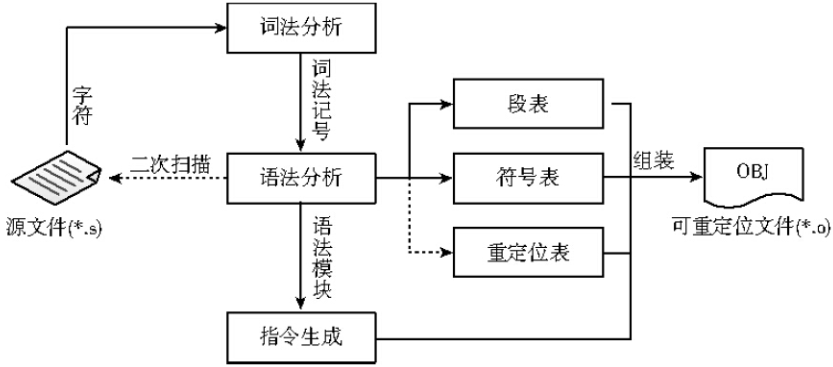
汇编器的词法语法分析
汇编器也包含词法分析、语法分析、语义处理、代码生成4个流程
相比于编译器,汇编器的工作重点放在目标文件信息的手机和二进制指令的生成。
汇编器和编译器最大的不同是汇编器需要对源文件进行两遍扫描,根本原因是汇编语言允许符号的后置定义。例如汇编语言常见的跳转指令:
|
|
第一遍扫描的时候,汇编器不知道L是否已定义
第一遍扫描是汇编器在获取符号信息
第二遍扫描汇编器才开始使用符号信息
表信息生成
汇编器的符号表记录了:
- 符号信息
- 段相关的信息
- 重定位符号信息
这些信息都是生成可重定目标文件所必须的
段表信息生成
对于段表信息,可以在汇编器识别section语法模块的处理
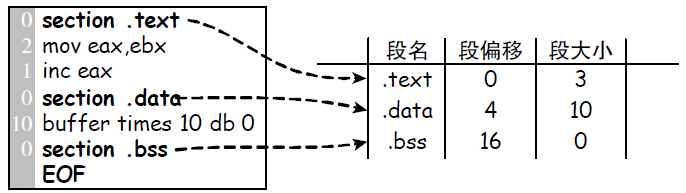
汇编器的语法分析器只要计算两次section声明之间的地址差,就能获取到段长度
从将段名称、偏移、大小记录到段表项内
如果按照4字节对其,需要对段便宜进行扩展
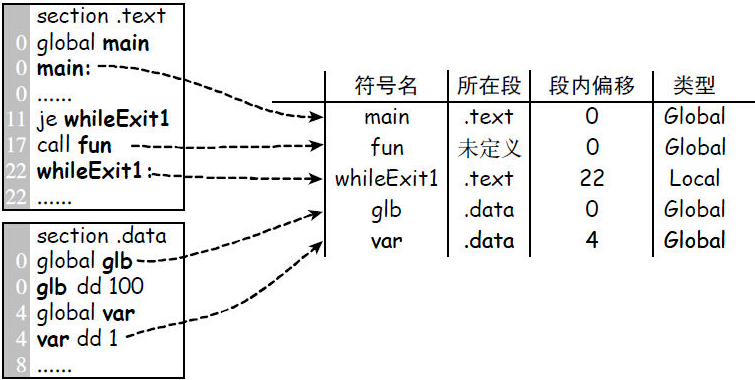
符号表信息生成
与ELF文件的符号表的区别:
- 汇编器的符号表来源于汇编语言定义的符号,
- ELF文件的符号表是汇编器根据需要导出的符号信息
如:使用equ定义的符号,对汇编器来说就是一个符号,但是在ELF文件内,它则是一个数字常量。
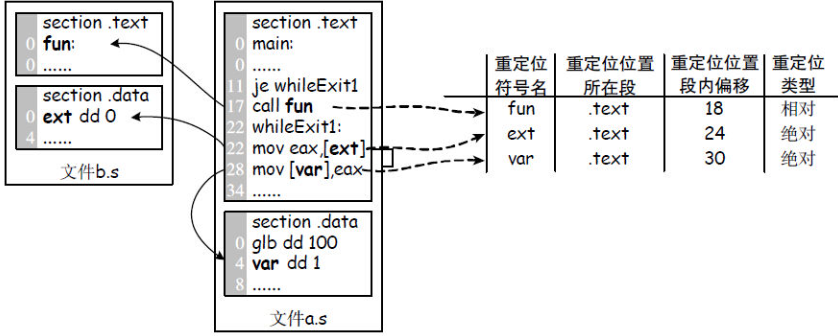
重定位表信息生成
目标文件连接时会重新组织代码段、数据段的位置。这样端内定义的素有符号的地址一级引用符号的数据和指令都会产生偏差,这时就重新计算符号的地地址,修改原来的地址,也就是常说的重定位。
重定位一般分为两大类:
- 绝对地址重定位
- 相对地址重定位
指令生成
在汇编器语法分析时,需要根据指令的语法模块手机这些指令的结构信息
比如:
- 操作码
- ModR/M字段
- SIB字段
- 偏移量
- 立即数
指令和操作码一般是一对多的关系
有些指令的ModR/M字段的reg部分和操作码有关。
除了正确输出指令的二进制信息外,汇编器在遇到对符号引用的指令时,还要记录相关重定位的信息
比如:
- 重定位地址
- 重定位符号
- 重定位类型
最后按照ELF文件结构,汇编器将手机到的端信息和二进制数据组装到目标文件内。