MySQL索引基础
索引
索引数据结构分类
- 二叉树
- 红黑树
- Hash
- B-Tree
- B+Tree
数据结构可视化连接: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉树 (Binary Tree)
原理: 二叉树是一种树形数据结构,每个节点最多有两个子节点。节点之间存在层级关系,从上到下排列,根节点是树的顶点。
优点:
- 结构简单: 二叉树结构直观、易于实现和理解,尤其适用于树形数据的表现。
- 插入和删除: 对于平衡的二叉搜索树,插入和删除操作可以在O(log n)时间内完成。
缺点:
- 不平衡性: 普通的二叉搜索树(BST)在插入顺序不当时可能会退化为链表,导致最坏情况下的时间复杂度为O(n)。
- 维护平衡复杂: 需要额外的算法来保持树的平衡,如AVL树或红黑树。
在MySQL中的应用: 二叉树本身很少直接用于MySQL索引,因为平衡性维护复杂且效率较低。实际应用中更常用的是改进版本如B树和B+树。
红黑树 (Red-Black Tree)
原理: 红黑树是一种自平衡的二叉搜索树,通过节点的颜色(红色或黑色)和一系列平衡规则来确保树的平衡。关键规则包括根节点为黑色、红色节点的子节点必须为黑色、从根到叶子的每条路径都包含相同数量的黑色节点等。
优点:
- 平衡性维护: 红黑树在插入和删除操作后,通过旋转和重新着色保持近似平衡,确保了最坏情况下的O(log n)操作时间。
- 效率稳定: 相比于普通二叉树,红黑树更能保证在各种情况下高效的插入、删除和查找操作。
缺点:
- 实现复杂: 由于涉及多种旋转和重新着色操作,红黑树的实现相对复杂。
- 内存占用: 每个节点需要额外存储颜色信息,可能会略微增加内存消耗。
在MySQL中的应用: MySQL内部不直接使用红黑树作为索引结构,但在InnoDB存储引擎中,红黑树常用于内存结构如缓存。
哈希 (Hash)
原理: 哈希表利用哈希函数将键映射到存储位置,通过哈希值快速定位数据。在发生冲突时,常用的解决方法包括链地址法(链表法)和开放地址法(再哈希)。
优点:
- 快速查找: 哈希表查找操作平均时间复杂度为O(1),对于等值查询非常高效。
- 插入和删除快速: 哈希表的插入和删除操作也非常高效。
缺点:
- 不支持范围查询: 哈希表不适用于范围查询,无法高效处理区间查找。
- 冲突处理复杂: 当哈希冲突频繁时,会影响性能,并且需要额外的冲突处理机制。
在MySQL中的应用: MySQL的Memory存储引擎支持哈希索引,适用于只需等值查询的应用场景。InnoDB存储引擎的Adaptive Hash Index(自适应哈希索引)利用哈希加速特定索引查找。
B树 (B-Tree)
原理: B树是一种平衡的多叉树,旨在保持数据有序,并允许顺序访问、查找、插入和删除操作。每个节点可以包含多个键和子节点。B树的所有叶子节点在同一层,确保了树的平衡性。
优点:
- 平衡性: B树通过多路分叉和节点分裂保证了树的平衡,插入、删除和查找操作的时间复杂度为O(log n)。
- 磁盘IO优化: B树节点通常设计为与磁盘块大小匹配,优化了磁盘IO性能。
缺点:
- 空间浪费: B树可能会有内部节点未满的情况,导致空间利用率下降。
- 实现复杂: 需要处理节点分裂和合并操作,复杂度较高。
在MySQL中的应用: MySQL的InnoDB存储引擎使用B树(具体为B+树)来实现其主键和二级索引。B树的平衡性和磁盘IO优化特性使其非常适合数据库索引。
B+树 (B+Tree)
原理: B+树是B树的变种,不同之处在于B+树的所有值都存储在叶子节点,内部节点只存储键值用于导航。叶子节点通过指针连接,支持顺序遍历。
优点:
- 顺序访问: 由于叶子节点通过链表相连,B+树支持高效的范围查询和顺序遍历。
- 高扇出: B+树的内部节点只存储键值,增加了每个节点的扇出度,减少了树的高度,提高了查询效率。
- 稳定性: 所有数据都存储在叶子节点,查询路径固定,性能更稳定。
缺点:
- 更新复杂: 插入和删除操作可能导致节点分裂或合并,处理复杂。
- 内存占用: 需要额外的链表指针,增加了内存开销。
在MySQL中的应用: MySQL的InnoDB存储引擎主要使用B+树作为索引结构。B+树的顺序访问能力和高扇出度使其非常适合数据库的索引需求。
B+树和B树的区别:
- B树的节点所有节点中都没有重复元素,但是B+树有, 存在冗余节点。
- B树的中间节点会存储数据指针信息,而B+树只有叶子节点才存储。
- B+树的每个叶子节点是有一个指向下一级的指针。
索引的存储
在MySQL中不同的引擎索引有着不同的存储方法
InnoDB
主索引(聚簇索引,Clustered Index):
- 聚簇索引特点: InnoDB使用聚簇索引将数据行与主键值存储在一起(存储在ibd文件中)。每个表必须有且只有一个聚簇索引,通常是主键。非主键列也被存储在主键索引中。
- 优点:
- 数据访问速度快,因为索引和数据一起存储。
- 范围查询高效,因为叶子节点通过双向链表连接。
辅助索引(非聚簇索引,Secondary Index):
- 辅助索引特点: 辅助索引用来加速非主键列的查询。辅助索引存储的是主键的副本,用于查找具体的数据行。
- 优点:
- 提供了对非主键列的快速查找能力。
- 缺点:
- 维护辅助索引需要额外的空间和时间。
MyISAM
主索引和辅助索引:
- MyISAM索引特点: MyISAM使用B树作为索引结构,索引文件和数据文件分离(MYD和MYI文件)。主索引和辅助索引的结构相同。
- 优点:
- 索引结构简单,容易维护。
- 适用于大量读操作的应用场景。
- 缺点:
- 不支持事务和外键。
- 更新和删除操作的性能较低,因为需要频繁的索引重建。
- 索引文件和数据文件分离,数据访问需要额外的IO操作。
稀疏索引与稠密索引
稠密索引
表中的每个搜索码值(对应着建立索引的时候使用的列名)都有一个索引项。
在稠密聚集索引中,索引项包括搜索码值以及指向具有该搜索码值的第一个数据记录的指针。具有相同搜索码值的其余记录顺序地存储在第一个数据记录之后。
例子: 找到第一条GZ02计4班的记录。
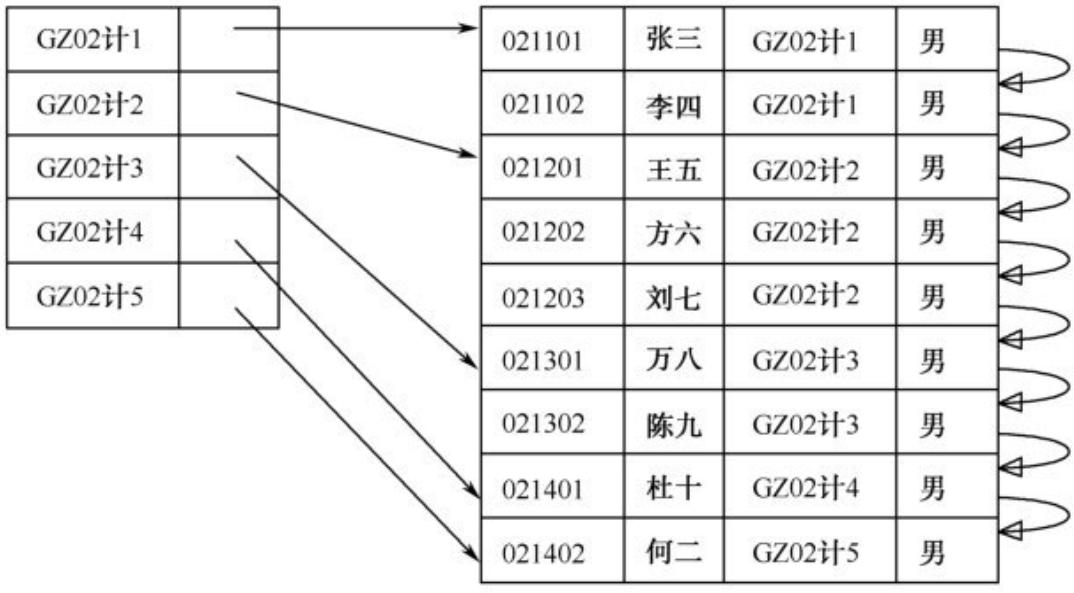
稀疏索引
只为某些搜索码值建立索引项。和稠密索引一样,每个索引项也包括一个搜索码值以及指向具有该搜索码值的第一个数据记录的指针。为了定位一条记录,我们找到其最大搜索码值小于或者等于所找记录的搜索码值的索引项。我们从该索引项指向的记录开始,沿着表中的指针查找,直到找到所需记录为止。
例子:
没有一个索引项对应于“GZ02计4班”。由于(按照班级顺序)在“GZ02计4班”前的最后一个索引项为“GZ02计3班”,沿着这一指针找到它所指的记录,然后顺着这条记录向下找,直到找到第一个“GZ02计4班”的记录,此时再开始进行处理
对于"GZ02计4班", 则需要从他前一个索引的最后一项开始找起
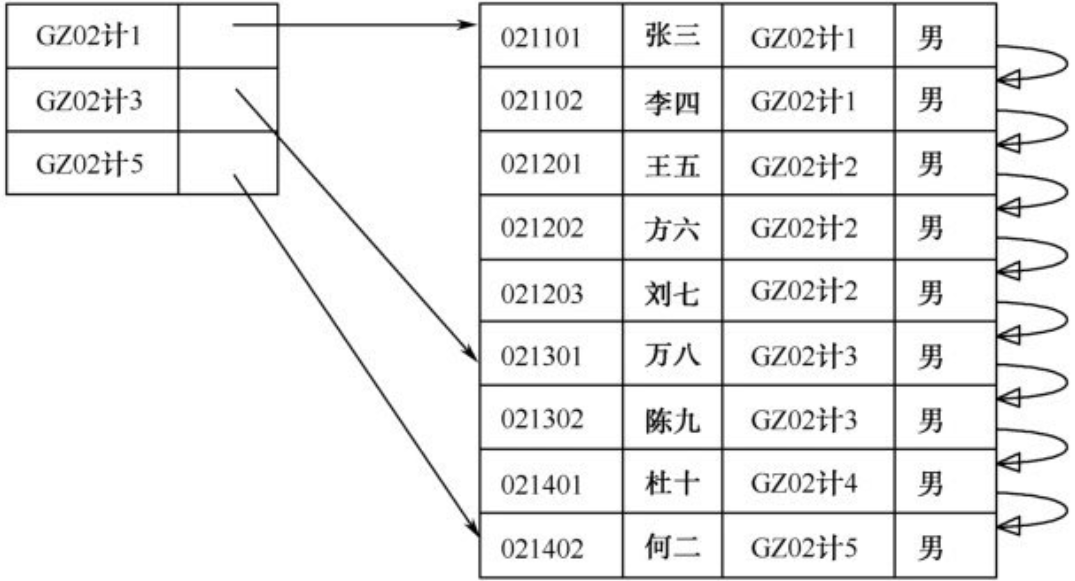
- 一般情况下稠密索引比稀疏索引定位的速度更快一点
- 稀疏索引占用的空间要小一点